Tokenization demo
This is a simple demonstration of an interactive tokenization algorithm: as you type words in the input box, the text is “tokenized” (split into words) and rendered in a numbered list.
- (tokens will appear here)
Patrick Hall
Although language documentation has evolved rapidly in recent years, in some respects its history is as old as writing itself. As explained in some detail in Chapter 2, a fairly consistent conceptualization of the most important units to use for analyzing the grammar of a language is traceable over the long arc of the study of “other languages”. These include a Corpus (a collection of texts); a Text (in a very general sense—any collection of linguistic utterances or other units); a Sentence (again, a very general notion, containing of a sequence of words) ; individual Words; and morphemes — the parts of words. While this small hierarchy (see Figure 1) is only the skeleton of an almost endless array of more complicated models of linguistic structure, its consistent use over thousands of years in documenting the meaning and structure of linguistic expression is a testament to its reliability and utility. Modern documentary linguists still make use of a conceptualization which is very much in keeping with this general outline.
Naturally, the terminology used varies. (The notion of the “Sentence,” in particular, is a highly contested and theoretically loaded one.) Because existing software tools in language documentation have distinct development histories, those tools tend to handle only a subset of the types of information captured within this hierarchy. Data for analysis at one level is generally not compatible with data at all of the other levels, and this lack of common data formats has proven to be a strong constraint on the ease of production and portability (Bird and Simons 2003) of the resulting documentation. Harmonizing data between multiple applications (one for text alignment, another for morphological analysis, another for phonetic analysis, etc.) is a painful process for any linguist who wishes to analyze data produced with two or more of those applications. Furthermore, many such tools are designed to work on only one or two of the three major operating systems in use today: Microsoft Windows, Apple OSX, and Linux. Because of these incompatibilities, the software ecosystem which has emerged can impede or even preclude many useful kinds of linguistic analysis: the design of the tools becomes in effect a constraint on which kinds of analysis can be carried out in an efficient and reproducible manner.
Despite this reliably useful conceptual model of documentary data, it is not as consistently implemented in the software tools used in modern digital approaches to documentation as might be expected. This dissertation is an attempt to offer one way to remedy this problem, by detailing a way to use this quasi-standard data model as the direct basis for implementing a functioning, extensible, powerful software ecosystem on top of the standard technologies which constitute the Open Web Platform.
The consolidation of characteristics of this platform is unprecedented in the history of technology: it is at once ubiquitous, standardized, open, and incredibly powerful. Its key technologies include HTML (Hypertext Markup Language), CSS (Cascading Stylesheets), the “JSON” data format, as well as the Javascript programming language itself, which is embedded in every modern web browser. (All of these are detailed in Chapters 2-5.) This platform offers a totally new degree of cross-platform interoperability not only for creating multi-lingual, visually advanced documents, but also for creating interactive applications: tools for getting work done. In the past several years the standardization of the platform seems to have passed a critical threshold. Today the platform is becoming a sort of operating system in its own right, but one which is available on an astonishing array of devices. The Open Web Platform is an obvious choice for creating documentation which will remain usable and portable in the future.
It would be presumptuous to imply that this dissertation is some kind of origin point for the concept of “doing” linguistics through the use of digital tools. It is not intended in that way. I do suggest the term, however, as a counterbalance to the other labels which lie at the intersection of human language and computation, namely “Natural Language Processing” (NLP) and “Computational Linguistics.” Both of these terms, now fairly distinct fields, refer to work which is predicated on the existence of large corpora in the language or languages to be studied. But in linguistics, and in documentary linguistics especially, it is often the case for external reasons (largely economic and political in nature) that there are no large corpora. Indeed, in the case of completely undocumented languages, there is nary a single record.
The term “Digital Linguistics” could be adopted to cover all aspects of the application of computer technology for building (and using, and re-using) corpora of hitherto underdocumented languages. Seen from this vantage point, Digital Linguistics is already a thriving field: as described elsewhere in this work, a panoply of software tools are being actively applied to documentation.
What I hope is new in this work, then, is one specific implementation of a
system intended to cover as much of the domain of language documentation as
possible in a unified fashion. I refer to this implementation (primarily
consisting of a library of Javascript code) as DLx. The ultimate “concrete” form
of this library is a Javascript file named dlx.js. This is simply my take
on one workable approach to Digital Linguistics writ large.
There is one more crucial goal of this dissertation: that it serve as a pedagogical tool for understanding exactly how the underlying technologies are being employed to create useful applications for documentary linguistics and revitalization. Unless the community of linguists who can understand, apply, and extend the principles developed here crosses some (unknown) critical size, the system described here will simply decay into disuse and irrelevance.
To combat that fate, the present work has also been created as an interactive document: it is somewhat unusual in that it is written as HTML, and contains interactive components. Because it deals with the topic of how to use the web platform to create future-proof canonical data formats which should remain readable and usable as long as the web itself remains useful, it seems an obvious choice for the dissertation itself to be “native” to that platform. Thus, the canonical format of the dissertation is HTML, with CSS enabling a web-based version of the standard notation for documentary linguistics, including among other features: interlinear glosses, paradigmatic tables, support for full phonetic notation and arbitrary orthographies through the use of Unicode. PDF and eBook versions are also maintained as part of the completed dissertation.
Note, however, that those formats should be understood as derived products for convenience, because what truly distinguishes this dissertation is the fact that it has, in addition to standard inline Figures, and Tables, an additional “component” which will be interspersed throughout the text: a “Demo”. Demos are interactive elements which appear directly within the dissertation when viewed through a web browser. Each Demo will be accompanied by a code listing, which I intend in all cases to be shorter than two pages. (As I describe below, I place a priority on keeping the technical details required to understand the dissertation as constrained as possible.)
Here, for example, is a simple example of a Demo, which interactively splits a sentence into individual words and renders them as a numbered list (that is to say, it tokenizes a sentence). The interface at the top is defined by the combination of HTML, CSS, and Javascript presented below the interface.
This is a simple demonstration of an interactive tokenization algorithm: as you type words in the input box, the text is “tokenized” (split into words) and rendered in a numbered list.
While the details here may seem overwhelming at first, the key idea to bear in mind is that this non-trivial application is defined solely in terms of the HTML, CSS, and Javascript presented above. The application is self-contained in the sense that it can be “reproduced” in any modern browser by loading that data as a web page. It can be distributed either over the web on a web server, or else as a set of text files which can be emailed or distributed via a physical medium. All of the code in this example, as well as the principles behind its design, is fully explained in this dissertation.
The system described, implemented, and explained herein includes a small set of applications which may be thought of as a sine qua non for the working documentary linguist: 1) an interlinear text editor which has full support for arbitrary orthographies; 2) a basic lexicon which is linked to the text editor in such a way that redundant annotations are automatically pre-populated; 3) integrated audio and media playback as well as an interface for aligning such media with the interlinear texts; and 4) the ability to search all of 1-3 in a useful and intuitive fashion. Beyond these fundamental applications, I demonstrate the application of this system to a handful of larger-scale projects in typology and revitalization.
Chapter 1: Introduction
I motivate the dissertation, situating digital linguistics firmly within the tradition of documentary linguistics, and emphasizing that it is a project with two parallel streams: firstly, it is a model of documentary data and workflows with an implemented set of applications for handling data within that model, and a parallel, equally important stream which consists of a pedagogical apparatus to not simply explain but also teach the way in which those applications work.
Chapter 2: Tablets, Tables, and Trees: Data structures and Documentation
Rather than making the details of programming the starting point, I begin by reconsidering familiar linguistic artifacts, but viewed through the lense of the notion of a “data structure”. Linguists already possess, of course, highly developed and flexible conceptualizations of linguistic structure. I suggest that the most fundamental of these structures are detectable in essentially all physical remnants of linguistic study, be they modern or even ancient. The goal of this chapter is to valorize the institutional knowledge of linguistic structure as well as the notational conventions — indeed, the notational technology — in which that knowledge has come to be expressed. Documentarians already understand the structure of their data, even if some of that understanding is on more of an intuitive level than a conscious one. The goal is to build a system to encode the existing conceptualizations into a computer (rather than allowing technological defaults dictate how our documentation should be structured).
Chapter 3: Electrons, Not Atoms: Using digital documentary data
This chapter gives a more detailed account of a handful of core data types for documentary data. These are introduced first conceptually, and then represented in the JSON syntax, a simple and easily learned syntax which can be used to serialize practically any data structure. The second aspect of this chapter is to show that, once encoded, these data structures can be used to carry meaningful (and otherwise difficult or tedious) linguistic analyses.
Chapter 4: Computers don’t have eyes: Implementing user interfaces
Here is where we begin to delve into the task of building applications. Where a “document” is meant to be read, an “application” is meant to be used to present, create, edit, or analyze data. That is to say, applications are interactive. In order to create applications with the Open Web Platform, a set of skills must be acquired: these involve an understanding of the browser’s Document Object Model (DOM) and Event system, and well as Javascript fundamentals including functions, classes, and logical operations or “control flow,” all of which will be explained here.
Chapter 5: Fundamental DLx applications
This will likely be the largest chapter in the dissertation, as it will contain a detailed exposition of the design, implementation, and use of several DLx applications which carry out real annotative and analytical tasks in documentation. The current document is essentially a laundry list of possible applications (although many are already either usable or in development). For the dissertation itself, a major part of the work will be ordering this sequence of expositions in a pedagogically meaningful way.
Chapter 6: The Cavalry Isn’t Coming
This final chapter, which I expect to be fairly short, will be something of a “call to arms” to the field. Having demonstrated in functional, transparent detail that it is possible to build useful, portable, interoperable applications with the Open Web Platform, I will turn to thoughts about how to proceed to strategize for the adoption of this approach to Digital Linguistics.
Swimming as we all are in a sea of information, it is difficult for modern linguists to extract themselves from the present and imagine a time when their work was not mediated in some way by computers. But a pair of quotes from early practitioners of language documentation bring the sea change from the age of paper to the digital era crashing home. Kathryn Klar (2002) tracked down a revealing insight into the working methods of J.P. Harrington, a linguist whose vast and ramshackle output needs no introduction. Klar recovered an outline by Harrington for a 1914 lecture on fieldwork methodology, perhaps the only explicit record of Harrington’s working methods. In the following quote, he describes how would-be field linguists should sort their fileslips (emphasis added):
The sorting of slips should be done in a large, windless appartments [sic] where the work will be undisturbed. Many Large tables are most convenient, although it often becomes necessary to resort also to placing slips on the floor. The sorting of many thousands of slips is a most tedious and laborious task. To many it is mere drudgery. It cannot well be done by anyone other than the collector. It is easy and interesting to record words on these slips by the thousand. The sorting however takes many times as long as the recording.
We imagine Harrington in a bleak rented room somewhere in California,
surrounded by his innumerable slips of paper, deathly afraid of a breeze
blowing away a year’s worth of careful organization of precious notes on Chumash or Ohlone.
Harrington was not alone in suffering the curse of “sorting”: it also plagued
Leonard Bloomfield, whose complaints of the ailment were recounted by Hockett
in Bloomfield (1967), (again, emphasis added):
Bloomfield was speaking of the tremendous difficulty of obtaining a really adequate account of any language, and suggested, half humorously, that linguists dedicated to this task should not get married, nor teach: instead they should take a vow of celibacy, spend as long a summer as feasible each year in the field, and spend the winter collating and filing the material. With this degree of intensiveness, Bloomfield suggested, a linguist could perhaps produce good accounts of three languages in his lifetime.
It turns out that Bloomfield did not live up to his own expectations: he did not live to see the publication of his one full-scale grammar, The Menomini Language, and it was Hockett who would edit and see through the posthumous publication of that work (Bloomfield 1969). While Bloomfield seems to have been speaking somewhat tongue-in-cheek, Harrington’s true evaluation of his own claim can of course be measured in (mostly unpublished) tons. But whatever the correct numerical interpretation of these admonitions, the import is clear enough: two well-known linguists agree in advising aspiring linguists to expect to spend a significant portion of their careers — perhaps one half of their careers — engaged in ‘sorting’ data.
It is humbling to imagine what such productive and prolific linguists could have achieved had they not been constrained in this way. One is reminded of the 18th-century lexicographer Samuel Johnson’s self definition as a ‘a harmless drudge’. Surely our easy modern access to relatively cheap and powerful computers obligate us to view hand-sorting in the era of computers to be drudgery of the “harmful” sort?
And yet, some modern linguists seem to exhibit a curious reluctance to let go of the old paper-based ways of documentation, or at least a lingering nostalgia for those methods:
The first dictionary I did (a preliminary version of my Mojave dictionary) was compiled in three-inch by five-inch slips (some linguists, I know, prefer four-inch by six-inch slips!) - not cards (too thick!), but slips of ordinary paper, which were arranged alphabetically in a file box (one hundred slips take up only a little more than half an inch). Reluctantly, I have stopped introducing field methods classes to the joys of using file slips, which I still feel are unparalleled for their ability to be freely manipulated and arranged in different ways. But I don’t use paper slips much myself any more, so it doesn’t seem right to require students to make a slip file, as I once did. (Munro 2001)
In a more explicit example of reluctance to embrace technology in fieldwork, hear R.M.W. Dixon:
In pre-computer days I’d fill in a 5 inch by 3 inch (12.5 cm by 7.5 cm) card for each lexeme. I continue with the same procedure today, as do many other linguists. Electricity supply is non-existent in many field locations, or else it is intermittent and unreliable. Reliance on a computer leads to frustration and a feeling of impotence when it ceases to work properly. This is why many linguists, working in difficult field situations, prefer to leave their computer back at the university. (Dixon 2009:297)
Both of these voices accept some role for computers, but resignation is not far from the surface: here we see experienced linguists looking dimly at the shift to the digital milieu: there is a loss of “joy,” replaced with “frustration,” and “a feeling of impotence.” (Note also the almost fetishistic specificity in the descriptions of the physical details of the paper medium.) Why is this? Would not Harrington and Bloomfield have given a king’s ransom for one of today’s mid-range, off-the-shelf laptops?
Those seeking support for carrying out fieldwork today are not permitted to vacillate on the question of whether to work digitally. Funding sources stipulate that corpora be deposited in digital form — fileslips and notebooks, nostalgia notwithstanding, are hardly acceptable academic output today. As the field of documentary linguistics has exploded — there are now many conferences focusing on or foregrounding language documentation — we have seen considerable progress toward the principles of “portable documentation” articulated in Bird and Simons’ seminal 2003 paper. In particular, significant progress has been made in archival practice. (For a useful history of these developments, see (Henke and Berez-Kroeker, 2016).)
But despite this intense activity in broadening the scope and improving the methodology of language documentation, the feelings of “impotence” and “frustration” seem to persist. Why do so many documentary linguists remain vexed by the difficulties of using computers to improve their research? Why is so much of our effort dedicated to troubleshooting software for doing linguistics, as opposed to simply doing linguistics? Is there something more behind Munro and Dixon’s complaints that the way we use technology in documentary linguistics is “joyless”?
There are standing answers to these questions: essentially, small groups of developers in research groups of diverse origin and motivations (from Max Planck to SIL) develop software which is intended to meet some of the needs of documentary linguists. These approaches have seen considerable success: ELAN, Toolbox, Praat, and other tools have made great contributions to the field: we are indebted to their creators.
For an overview of the capabilities of most server-based and desktop-based tools, see Dunham (2006). The software landscape described in there, which still obtains today, is a large suite of tools, each with a distinct set of file formats, covering distinct areas of the whole topical domain of documentary linguistics. Some cover the analysis of words (FieldWorks Language Explorer (FLEx), Toolbox), others the alignment of transcriptions and recordings (ELAN, Audacity), others building web interfaces to lexical information (WeSay), and so forth. (Dunham’s own Online Linguistic Database, described in Dunham (2006), is a very capable server-based tool with advanced morphological parsing and collaboration capabilities.)
But even in the face of this large ecosystem of tools, there is still much room to improve the ways in which we build up, interact with, and use data in language documentation. It is easy to enumerate desiderata for documentary software, but practical questions pile up even more quickly: What, exactly, will the software do? How will it be designed? Who will implement it? Who will maintain it? Who will train newcomers to use it and improve it?
This question is at the heart of this dissertation: is the solution to improving the difficulties that documentarists face in producing, using, and re-using their data to create yet another single, monolithic software tool, which will be maintained by a single, small group of developers? I answer this question in the negative. Rather than try to concentrate our efforts on training linguists and other language workers as users, we should shift our basic orientation to one in which we foster a community of development, within which the understanding necessary to define, build, use, and improve software is widely distributed: we need a sort of Cambrian explosion in the design of interfaces and applications which are small, well-defined, and composable.
Such an approach, as far as I can see, is only possible now, and only possible because the Open Web Platform can “multi-task”: it is simultaneously a platform which enables the development and use of applications for language documentation. It is one thing to train linguists to use a piece of software for documentation, it very much another to train them in the tools necessary to understand how that software works.
In order to launch this project, we must first develop a set of well-defined, flexible
abstractions which correspond to the conceptual units underlying language documentation.
A small set of such abstractions (the basic abstractions being Word, Sentence, Text,
Corpus and Lexicon) is sufficient to underlie a vast array of applications.
Rather than allowing the implementation of particular software tools (be they desktop- or
server-based) to impose conceptual categories on the user, a system where all
applications are built to manipulate the same basic abstractions (and which are also
capable of defining complex abstractions such as ComparativeLexicon) will
enable experimentation and iterative development of new, henceforth unseen tools for
doing and using documentation.
The pressures from language endangerment on this endeavor are real, and ever-increasing. As linguists, we owe it to the communities we work with to make our data as reusable as possible for varied ends, and this means that we will have to build tools quickly and efficiently. It is a group effort. We, as linguists, must learn to develop software to meet our own needs, as a group. We will do this by incorporating software development methodologies into documentary linguistics directly. Spreading out the effort and understanding required to build linguistic software among many documentarians is the best way to ensure that not only our software, but also the data produced with it, will be resistent to the vicissitudes of funding, bureaucracy, technological churn, and other maddening realities.
This is a long-term goal. It will require that a significant number of linguists commit to the the task of learning to develop software directly. Obviously, the demands of academia will limit how much time and resources any given linguist can dedicate to this task, but even those who are unable to dedicate the time to learn to develop software in the vein described below independently can benefit from the availability of a system which is widely understood.
Two equally important components are required to make this possible:
The first is a core application suite. This will consist of a a specific, coherent, functioning system of interoperable applications (in the form of Single-page Open Web Platform applications) which handle the core data types in common use in digital documentation. This may seem like an impossibly tall order. Fortunately, we are far from starting from scratch. I describe below how we can build on the incredibly robust infrastructure of the Open Web Platform to build the tools we need.
An accompanying pedagogy. The second component — again, equally important to the first — is essentially a pedagogical one. Simply releasing another software package to the documentation community without making a simultaneous effort to educate users on how the software actually functions is not the most future-proof approach. This dissertation is intended to be, to a significant extent, a how-to, a do-it-yourself guide, a vade mecum.
A primary motivation of Digital Linguistics is to help linguists understand that adopting a thoroughly digital approach to their data is both worthwhile and within reach, even for those linguists who might not have a background in programming.
In keeping with this motivation, I aim to show how the very same conceptual constructs which have long served as the basis for language documentation can also be thought of as data structures: standardized ways of organizing types of information. Note that in computer science, the term “data structure” may have a more elaborate definition, related to computational complexity. Here, however, all higher-level data structures will be composed in terms that may be expressed as combinations of two generic structures: objects and arrays. A primary task of Digital Linguistics is to develop a methodology of analyzing linguistic data in such a way that documentary data structures may be recorded explicitly in terms of these generic structures.
Accordingly, I begin by surveying a sample of physical artifacts which encode or serialize data structures. Aside from their inherent interest, comparing these artifacts reveals, over and over, that the same familiar, fundamental units of linguistic structure have been used and re-used by scholars of language in essentially all contexts where writing has been employed. Note that this fact can be interpreted to mean that the notion of a data structure, — conceived of as pieces of information with defined interrelationships — has, in principle, nothing to do with a computer per se. It is simply a rather reductionist representation of classes of things.
I will develop the following core data structures:
| Text | an array of Text objects |
|---|---|
| Sentence | an object containing a transcription and translation, plus an array of Words |
| Word | objects containing at least token and gloss attributes |
| Lexicon | an array of Words |
| Corpus | an array of Text objects |
| Language | an object containing phonetic, orthographic, and other information. |
(For details of these data structures, see chapter 3).
But rather than beginning with an introdution to these data structures as generic “containers” (as most introductions to programming do), my approach will begin firmly in the domain of language documentation.
A wide variety of technologies has been employed to record the linguistic information yielded by the study of human languages, and it is the embodiment of that knowledge in a persistent physical form which is the true origin of what is today called “documentation.” The particular goals of recording the grammar and use of languages (as opposed to literature or other forms of monolingual prose) shaped the physical forms that documentary artifacts took. As demonstrated in the brief survey below, both the nature of the information which it is possible to store and the range of uses to which that stored information may profitably be put are strongly constrained by the form of the storage medium itself: certain kinds of documentary artifacts afford encoding and recovering certain kinds of linguistic information, while the same artifact may make other kinds of analysis or use impracticable or impossible. Ironically, tracing the constraints that particular (physical) documentary formats impose on the information they contain simultaneously serves to reveal a handful of key kinds of data which have proven useful throughout the long history of the study of language: unsurprisingly, these correspond fairly directly to fundamental units of linguistic analysis such as ‘word,’ and ‘sentence.’
This tablet is one of several which constitute what is arguably the oldest bilingual dictionary. Even to readers who are unfamiliar with the languages (Sumerian and Akkadian) and the writing system (cuneiform), it is not difficult to see that this document has two columns. And indeed, it is the conventionalized physical layout (or “format”) of the information which conveys the meaning between each each Sumerian word with its Akkadian translation: each word in the left-hand column is matched up horizontally to an Akkadian word in the right-hand column. In this document, the “link” between the Sumerian and Akkadian forms is conveyed solely through formatting: the data structure is quite literally carved into the clay.

There are really three elements per row in this table, not two: we have a Sumerian word, an Akkadian word, plus the translational relationship that is implied between them.
This example is chosen precisely because the cuneiform text is likely to be illegible
to most modern readers. Although the text is illegible, the format, or structure,
of the clay tablet is to some extent recognizable, if not by viewing the left-hand
photograph of the tablet, then more so through the center and right-side drawings
of the same tablet. Once a linguistically-informed reader is told that the tablet
contains a bilingual lexicon, and shown these renderings, it is not difficult to
appreciate that the document is comparable to a spreadsheet. Indeed, it the tabular
rendering below (in fact, created with an HTML table tag) contains the first five
lines of the tablet, in transliteration, first with the Sumerian “headword,” then
the Akkadian gloss (and with a modern English gloss added by Spar et al).
| Sumerian transcription | Akkadian translation | English translation |
|---|---|---|
| udu.níta | im-me-ru | sheep |
| udu.ni-gu ŠE | MIN ma-ru-ú | grain-fed sheep |
| udu.ŠE.sig₅ | MIN MIN dam-qa | grain-fed beautiful sheep |
| udu.gír.gu.la | ar-ri | sheep “for the big knife” |
| udu.gír.ak.a | kaṣ-ṣa | shorn sheep |
This layout, so reminiscent of a modern two-column spreadsheet, is by
no means the only conventionalized format that expressed a
translational relationship. In the first page of the late 18th century Yuzhi Wuti Qing Wenjian
or Manchu Polyglot Dictionary (Yong and Peng 2008:397-398), below, a quite different format is used. Here
entries in five languages (Manchu, Tibetan (three distinct transcriptions),
Mongolian, Chagatai (two transcriptions), Chinese) are arranged vertically
in columns rather than in rows. Setting aside for now the question of
how to handle the data representing the numerous transcriptions and transliterations
of individual languages (but see chapters 3 on the Word and Sentence data types
and Chapter 5 on example applications which handle data in multiple orthographies
and “compound” comparative dictionary data), the translational relationships are quite
comparable to those in the Mesopotamian lexical list.

If such divergent historical instantiations of documentary data can truly be “reconceptualized” in terms of data structures, in what digital format should that commonality in data structures be stored?
I propose the flexible yet expressive JSON (Javascript Object Notation),
which has become a very popular format for data exchange both between
programming languages and over the internet. Briefly, JSON is a syntax
for serializing arbitrary textual and numeric data in terms of objects
and arrays. The objects and arrays may in turn contain one of four so-called “primitive”
varieties of values: strings, numbers, booleans (either true or false),
and null (an empty value). Strings must be encoded acccording to Unicode
(JSON thus supports data in almost any writing system, including IPA). Numbers
may be plain integers or “floating point” (decimal) values. Booleans (named for
the logician George Boole) are used to represent yes/no values, and finally,
it supports a null value, a rather peculiar concept which represents
the absence of a value (comparable in meaning, say, to a ‘null-marked’ third
person marker commonly notated ∅ in interlinear glosses).
Beyond these four kinds of “primitive” values, JSON supports arrays and
objects. JSON objects are { enclosed in curly brackets } and
contain comma-delimited "key": "value" pairs, in turn separated
by colons:
{
"key": "value",
"anotherKey": "another value"
}
JSON (and Javascript) Arrays are [ enclosed in square brackets ] and may
contain any either quoted strings (as below):
[
"udu.níta",
"udu.ni-gu ŠE",
"udu.ŠE.sig₅",
"udu.gír.gu.la",
"udu.gír.ak.a"
]
…or a list of comma-delimited objects. Thus, the spreadsheet above may be represented with no loss of information as JSON in the following way:
[
{
"glosses": {
"akkadian": "im-me-ru",
"english": "sheep"
},
"token": "udu.níta",
"gloss": "im-me-ru"
},
{
"glosses": {
"akkadian": "MIN ma-ru-ú",
"english": "grain-fed sheep"
},
"token": "udu.ni-gu ŠE",
"gloss": "MIN ma-ru-ú"
},
{
"glosses": {
"akkadian": "MIN MIN dam-qa",
"english": "grain-fed beautiful sheep"
},
"token": "udu.ŠE.sig₅",
"gloss": "MIN MIN dam-qa"
},
{
"glosses": {
"akkadian": "ar-ri",
"english": "sheep “for the big knife”"
},
"token": "udu.gír.gu.la",
"gloss": "ar-ri"
},
{
"glosses": {
"akkadian": "kaṣ-ṣa",
"english": "shorn sheep"
},
"token": "udu.gír.ak.a",
"gloss": "kaṣ-ṣa"
}
]
Note here that the value of the key glosses in each word object is itself
a complex JSON object. This ability to “nest” complex structures — that is,
to encode tree structures — is a crucial feature of JSON, as many of the most
common structures in documentary data are related through hierarchy.
As for the keys themselves (here: glosses, akkadian, english, and especially
token and gloss), these are important decisions which will require further
discussion and justification Chapter 3. Suffice it to say that the goal is to make
the data structures as familiar as possible to any documentary linguist. While JSON
files aren’t meant to be edited directly, they should be as human-readable as possible.
(Note that in the JSON above, the default “translation” for each word, in keeping with the clay tablet source, is in Akkadian, not English. Thus, this file will be of great use to any Akkadian-speaking scribe who takes up Digital Linguistics, as the default gloss is in Akkadian. Obviously, such decisions are project-dependent! And for said Akkadian scribe, on the funding from the local ziggurat.)
Again, lack of familiarity with these numerous writing systems does not change the fact that the structure of the entries are inferrable from purely visual information. The fact that this particular dictionary was typeset vertically is irrelevant to the (abstract) data structure which relates the terms to each other.
As effective as lexical lists on tablets were for storing Sumerian words with their translations, they were surely inconvenient when it came to searching for the meanings of words. The extract above is from the Urra=hubullu, a dictionary which was arranged into semantic classes (the example is from Tablet XIII, which enumerates types of sheep (Oppenheim and Hartman 1945)). Such works became literary objects in their own right: they were copied and recopied, with scribal students essentially memorizing Sumerian words as a long list. As spoken Sumerian died out and transformed into a literary and liturgical second language, these lists must have become increasingly difficult to use, given that there was no way to “look up” — to systematically search for — Akkadian translations: that is, there is no evidence of a reverse Akkadian-Sumerian clay tablets. (The practical demands of producing such objects would have been overwhelming!)
Of course, the convention of sorting words into “alphabetical order” has long since been used as a means of making search easier. A couple thousand years forward in history, documentary linguists made use of alphabetization to ease the process of finding collected data about any of the many forms collected in fieldwork. This process, too, had its physical correlate: the “slip file” or “shoebox” dictionary. A typical example from the work of Robert Oswalt on Kashaya Pomo is shown below.
A very simple example is comparable in informational complexity to the Sumerian/Akkadian lexicon (let us ignore for now the small handwritten notations at the bottom of the card; these are references to speaker attestations and cognates in other Pomo languages):

This document records the fact that the Kashaya Pomo word k̓ili means ‘black or dark color.’ More commonly, however, fileslips accumulated a more baroque, not to say motley, array of information:

Despite this complexity, the slip file dictionary was often arranged alphabetically by the language of study. For the purposes of using the slip file dictionary, in other words, the content of the slip file above for the word síːṭóṭo ‘robin’ is treated as if it contained only the form and its gloss.
One of several such boxes from the slip file dictionary Oswalt produced in collaboration with Essie Parrish, Herman James, and others, is below.

There are about a dozen boxes in this slipfile dictionary, but of course the specific way that these boxes subdivide the whole array of file slips into boxes is largely meaningless, linguistically speaking. Like the fact that more English words begin with s than w, the way that these words are are distributed across the whole slipfile is a function of the conventional arrangement — the collation — of the sorting order that Oswalt designed.
While this document is far more detailed in terms of linguistic and paralinguistic information than the highly conventionalized content of the Sumerian/Akkadian lexical list, in the physical format in which it has come down to us, it suffers the very same drawback: the data is sorted only by the target language term.
It is no easier to find the Kashaya word for ‘robin’ in Oswalt’s slipfile than it is
to find the Akkadian name (the “gloss”) of a particular Sumerian word in the lexical list. Although both the
clay tablet and the slilpfile correspond to the notion of an Array — an ordered list —
the fact that both are “implemented” as physical objects (atoms, not electrons) means
that their utility is constrained in the very same manner.
Samarin (1967) is perhaps unique in the history of linguistic fieldwork manuals, as it gives a highly detailed account of how to produce and sort fieldwork data in a time when computers existed, but were not widely available. Samarin and other linguists (see for example Grimes (1959)) understood that arranging lexical or textual data on fileslips into a sorted slip file dictionary was insufficient for finding the intersection of data attributes of individual entries. Accordingly, they made use of another revealing “physical database,” although one which is far less well-remembered today than the slipfile. This mechanism was known as an “edge-notched card file”.
A typical edge-notched card produced by Samarin was as follows:
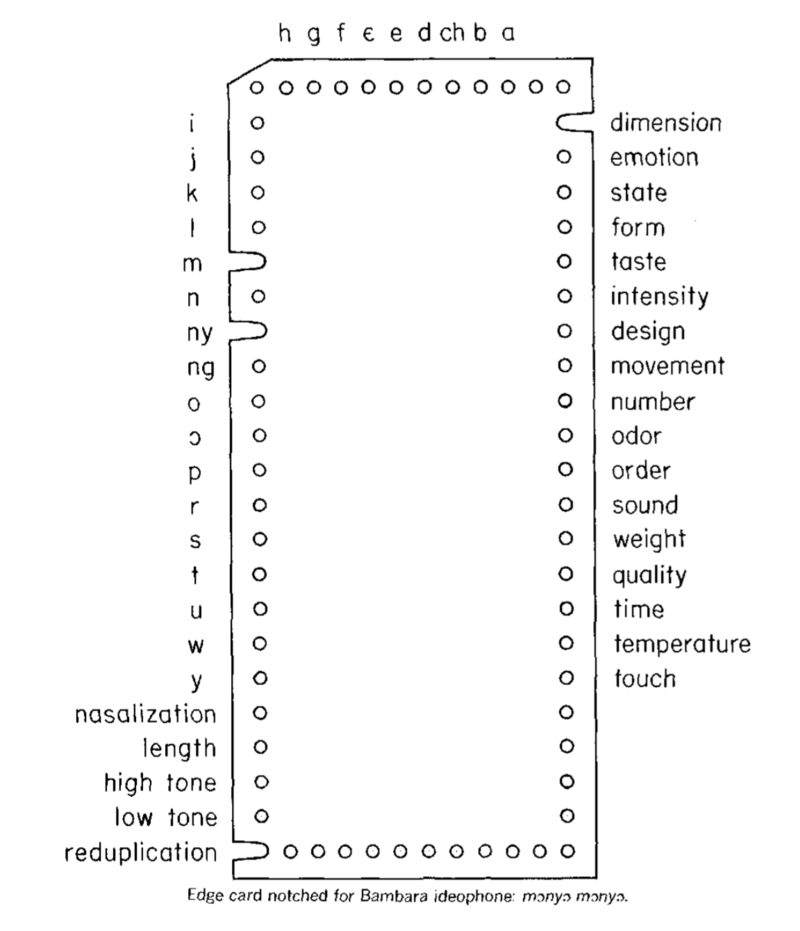
In Samarin’s usage, each card corresponded to an individual words — specifically, ideophones — in the Bambara language. A set of predetermined categories are represented as holes in a specific location on each card. If a given word “has” a given value for a given category, then a the hole was notched (cut away), making it retrievable using a batch-lookup with a knitting needle, as in the following image:

In the case of Figure 8, to select cards which begin with [m],
one would filter out all cards which are not notched at that label,
leaving only those which are so notched.
Not depicted in the previous image is the fact that the filtered cards could
be filtered again, perhaps to find those that were “marked” (notched) for
the phoneme spelled, in Samarin’s orthography, «ny». The intersection of the
two searches would match the card above, which represents the Bambara
ideophone mɔnyɔ mɔnyɔ.
These cards were used to carry out some geniunely original linguistic research - Grimes (1959) analyzed Huichol tone, Samarin described Bambara ideophones. But the attribute values Samarin used had to be defined before he printed his cards, and once they were printed they were hard to extend. So while this “concrete” data structure brought some new functionality to the table, it had physical limitations as well.
One way to represent this information as a data structure would be to use
an Object in JSON, such as the following:
{
"low tone": false,
"high tone": false,
"length": false,
"nasalization": false,
"y": false,
"w": false,
"u": false,
"t": false,
"s": false,
"r": false,
"p": false,
"ɔ": false,
"o": false,
"ng": false,
"ny": true,
"n": false,
"m": true,
"l": false,
"k": false,
"j": false,
"i": false,
"reduplication": true,
"touch": false,
"temperature": false,
"time": false,
"quality": false,
"weight": false,
"sound": false,
"order": false,
"odor": false,
"number": false,
"movement": false,
"design": false,
"intensity": false,
"taste": false,
"form": false,
"state": false,
"emotion": false,
"dimension": true,
"ɑ": false,
"b": false,
"ch": false,
"d": false,
"e": false,
"ɛ": false,
"f": false,
"g": false,
"h": false
}
An array of such objects would be equivalent in information to Samarin’s physical edge-notched card file, and would permit (as per the description of searching in Chapter 3, below) searching by combinations of attributes, just as Samarin carried out with his “physical” searching of the notched cards: “which ideophones contain m and ny and are also reduplicative and indicate ‘dimension’?”
It is important to bear in mind that in modern, digital language
documentation, the constraints of physical form on information content
did not simply evaporate. They linger, sometimes in obscure ways,
embedded in our practices, even coded into our software.
Bird and Simon make the following remark on the shift to the digital
medium (Bird and Simon 2003):
While the large-scale creation of digital language resources is a recent phenomenon, the language documentation community has been active since the 19th century, and much earlier in some instances. At risk of oversimplifying, a widespread practice over this extended period has been to collect wordlists and texts and to write descriptive grammars. With the arrival of new digital technologies it is easy to transfer the whole endeavor from paper to computer, and from tape recorder to hard disk, and to carry on just as before. Thus, new technologies simply provide a better way to generate the old kinds of resources.
Is this so? The suggestion that there is nothing more to digital documentation than a wholesale transfer from one medium to another is not terribly encouraging, although see Bird and Simons (2003) for constructive follow-up observations. In any case, their reference to wordlists, texts, and grammars is clearly a reference to the well-known “Boasian trilogy,” long considered the sine qua non of a complete documentary corpus.
However, in practice, the wordlist or dictionary component of the trilogy has been often been neglected. This curious state of affairs is perhaps explained by Haviland (2006), who observes:
In the Boasian trilogy for language description of grammar, wordlist, and text, it is surely the dictionary whose compilation is most daunting.
And indeed, Chelliah and De Reuse (2010) point out the seeming contradiction that the promoters of the the “Boasian” trilogy did not themselves publish many dictionaries (emphasis added).
It is remarkable… that Franz Boas himself collected a monumental number of texts … and wrote several major grammars, many grammatical sketches, and several short vocabularies, but never published anything that looks like a dictionary.
It is interesting to note Chelliah and De Reuse’s choice of wording:
anything that looks like a dictionary.
And
yet, it is hard to argue that Boas’ collected works do not contain
the “raw materials” of a dictionary in the form of word-level
glosses. If we reconsider the data structures which are implicit
in Boas’ typeset presentation of interlinear texts as shown below,
it is clear that Boas did document enough lexical information
to serve as the basis for a dictionary — considered in toto, the
individual per-word glosses which accompany his texts constitute a
formidable lexicon. (Albeit without modern morpheme-level annotations.)

In a well structured documentary database, the same “piece of information” —
a token, a gloss, a sentence — may simultaneously instantiate more
than one grammatical or linguistic category. That is to say, a single stretch
of text (a string) may be considered to be a token of more than one type, and grouped
now as a token of one type, now as a token of another, as analytical goals demand.
While these glosses do not constitute full dictionary entries, and their arrangement
as interlinear glosses indeed do not “look anything like a dictionary,”
they constitute lexical information just as legitimate as that contained in the very
different presentations in the Mesopotamian clay tablet or Manchu Pentaglot dictionary.
In summary, a brief analysis of the data structures “behind” all of these documentary artifacts can be thought of independently of their presentation. As examples in Chapter 5 will demonstrate, this independence of data from format is in fact very freeing: the same documentary data stored in a JSON file can be a single, canonical source for multiple uses, whether those uses be an interlinear time-aligned text for close linguistic analysis, or a pedagogical tool such as a game for language revitalization purposes.
Thus far, I have largely assumed a set of “linguistic types” without
committing to a list of such types or to a description of their internal structure.
While extensibility in the data model underlying DLx is certainly a goal,
a small inventory of simple, generic linguistic types, together with an enumeration
of their required attributes and hierarchical relationships, is essential to
enabling simple implementation of the core application suite. For example, an application for
transcribing wordlists should not build on a definition of the Word which is
at odds with the definition used to implement some other application, such as a
interlinear text editor. I will refer to this small set of fundamental data types
as the main data types for DLx. These data types will be built up in terms of
Objects and Arrays, the two highly generic data structures which constitute
JSON.
Before addressing the main data types of DLx, let us consider the important topic of how metadata is to be represented in the system. A constant challenge for documentary linguists is the ubiquitous difficulty of keeping metadata associated with the right database materials or files. One approach that has been advocated for documentary linguists is to develop a strict file-naming scheme which encodes crucial metadata such as topic, speaker, date, and so forth directly into a filename. In the experience of this author, this turns out to be a horrible idea.

Instead, I advocate an approach to handling metadata wherein metadata is itself represented
as a JSON object, alongside the data which it describes. In this case, an object called metadata
is at the top level of a JSON structure representing the Text instance.
{
"language_code": "hil",
"identifier": "001",
"speaker": "JDL",
"recording_date": "2017-03-09",
"creator": "JDL",
"description": "catching fish in Santa Barbara",
"format": ".wav"
}
Such objects are seen as values for the metadata key on the example
objects in the next section.
Language
Basic metadata about a language (names, language codes, phonological inventory, orthographies).
{
"metadata": {
"language": "Kashaya Pomo",
"iso": "kju",
"glottolog": "kash1280",
},
"orthographies": [
{
"ipa": "p",
"oswalt": "p"
},
{
"ipa": "b",
"oswalt": "b"
},
{
"ipa": "t̪",
"oswalt": "t̪"
}
],
"inventory": [
{
"name": "voiceless bilabial plosive",
"voicing": "voiceless",
"place": "bilabial",
"manner": "plosive",
"letter": "p",
"cv": "consonant"
},
{
"name": "voiced bilabial plosive",
"voicing": "voiced",
"place": "bilabial",
"manner": "plosive",
"letter": "b",
"cv": "consonant"
},
{
"name": "voiceless dental plosive",
"voicing": "voiceless",
"place": "dental",
"manner": "plosive",
"letter": "t̪",
"cv": "consonant"
}
]
}
Note that this structure includes featural information about the phonetic inventory of the language (which could be collected via an application such as the one in §5.5, below). This information may be used in a range of analytical tasks.
Word
Minimally, a word requires a token and a gloss. Note that there is a key
distinction between the occurrence of Word within a Sentence, and a Word
within a Lexicon. The former is a token, and the latter is a type. While there
is much ink to be spilled about the theoretical status of these concepts, in
practice and in developing prototype applications, this minimalist
definition of a ‘word’ has proven sufficient. Returning to a Sumerian example,
this time with an English-speaking linguist replacing our Akkadian-speaking scribe,
a simple instance of a Word might be:
{
"token": "udu.gír.ak.a",
"gloss": "shorn sheep"
}
Text
From the Word we move two levels “up”, to a Text. Below is an extract of
two sentences from the remarkable Ubykh texts of the famed last speaker of
Ubykh, Tevfik Saniç. The content is from an excellent web archive at LACITO-CNRS.
This structure, which is admittedly rather difficult to read as JSON, encodes two sentences from
an Ubykh text, plus metadata about that text. This Text object has a sentences
key whose value is an array, and within that array there are two objects, each
representing a Sentence object. The Sentences in turn contain an array of
Words, with a structure as given in the previous section.
{
"metadata": {
"title": "Eating fish makes you clever",
"linguist": "Dumézil, Georges",
"language": "Ubykh",
"speaker": "Saniç, Tevfik",
"archive": "LACITO-CNRS",
"notes": ["This is only a sample of the Ubykh text",
"Contains only the first 2 sentences"],
"media": "http://cocoon.huma-num.fr/data/archi/6537_POISSON_22km.wav"
},
"sentences": [
{
"transcription": "fạ́xʹa tˀq˚ˀá-k˚ábǯʹa kʹˀáɣə.n
aza.xʹa.šʹə.na.n á-mɣʹa.n gʹə.kʹa.qˀá.n.",
"translation": "Two men set out together on the road.",
"words": [
{ "token": "fạ́xʹa", "gloss": "un jour" },
{ "token": "tˀq˚ˀá-k˚ábǯʹa", "gloss": "deux hommes" },
{ "token": "kʹˀáɣə.n", "gloss": "en compagnons" },
{ "token": "aza.xʹa.šʹə.na.n", "gloss": "étant devenus l'un pour l'autre" },
{ "token": "á-mɣʹa.n", "gloss": "en chemin" },
{ "token": "gʹə.kʹa.qˀá.n", "gloss": "entrèrent sur" }
]
},
{
"transcription": "a.fawtə́.nə mɣʹáwəf a.x˚ada.wtən
a.kʹˀá.na.n á-za.n faċˀ.ạ́la s˚ə́ḇ.ạla x˚ada.qˀá.",
"translation": "They bought some provisions for the
journey. One bought cheese and bread,",
"words": [
{ "token": "a.fawtə́.nə", "gloss": "pour eux manger" },
{ "token": "mɣʹáwəf", "gloss": "provision de route" },
{ "token": "a.x˚ada.wtən", "gloss": "eux pour acheter" },
{ "token": "a.kʹˀá.na.n", "gloss": "étant allés" },
{ "token": "á-za.n", "gloss": "l'un" },
{ "token": "faċˀ.ạ́la", "gloss": "et fromage" },
{ "token": "s˚ə́ḇ.ạla", "gloss": "et pain" },
{ "token": "x˚ada.qˀá", "gloss": "il acheta" }
]
}
]
}
In addition to Language, Word, Sentence, and Text, the two remaining main data
types are Corpus and Lexicon. The Corpus contains a collection of
Texts, and the Lexicon contains a collection of words. There is of
course much more to be said about the structure and use of all of these
data types.
To this point the dissertation will have advocated the use of structured data and its relationship to traditional conceptualizations of linguistic units as employed in language documentation. But assuming that a corpus of non-trivial size can be assembled in this manner, what benefits will that structured corpus accrue to linguists (and linguistics), both in terms of expediting fieldwork methodology, and in terms of making data more amenable to analysis?
While the main introduction to programming basics in Javascript will be introduced in Chapter 4, at this point I will introduce the notion of a function, as it is indispensable for discussing the sorting, searching and analysis of data.
A function is a procedure which which takes input and either returns something else, or modifies something else. Here is a simple Javascript function that determines whether its input is one of a, e, i, o, or u:
let isVowel = letter => {
return [ "a", "e", "i", "o", "u" ].includes(letter)
}
Let us ignore the details of how this is implemented for the moment, and consider only how it is used:
isVowel("a")
This “returns” the boolean value of true, while:
isVowel("x")
…returns false. This sort of named procedure is key to implementing a whole
range of analytical operations over data.
The simplest “search engine” in Javascript is simply to “filter” an
array. Considering five Akkadian glosses from chapter 2, we may use our
previously defined isVowel function to create another function
which determines whether a word starts with a vowel.
let startsWithVowel = word => {
let firstLetter = word[0];
if(isVowel(firstLetter)){
return true
} else {
return false
}
}
Note that isVowel is called within the definition of this function.
And now we can pass this criterion directly to an array filter, as follows:
[
"im-me-ru",
"MIN ma-ru-ú",
"MIN MIN dam-qa",
"ar-ri",
"kaṣ-ṣa"
].filter(startsWithVowel)
The return value of running this filter will be another, containing only vowel-initial strings:
[
"im-me-ru",
"ar-ri"
]
While there is a fair amount of detail to understand here, once understood, this pattern is tremendously powerful. Far more complex analytical options can be built up from simple component functions combined into complex filters.
Sorting arrays of data is a surprisingly powerful task in data analysis.
Unlike a shelf of clay tablets or a box full of file slips, abstract Arrays
of Objects may be sorted by any criterion which can be defined in terms of
the set of attributes on each arrayed object.
In this section I will explain the conceptual background to sorting. In
most modern programming languages, the task of sorting is represented in a
very simple way: the programmer defines a procedure which answers the question
“Are these two items in order, out of order, or equal in order?”. If the
programming language is provided with (1) an array to be sorted and (2) such
a procedure (often called a comparator function), then all the details of
how to carry out the actual reorganization of data in the computer’s memory
is abstracted away. Like many modern programming languages, Javascript comes
with a set of built-in algorithms for carrying out a sorting routine, one of which
is chosen as appropriate to the characteristics of the data to be sorted. The
details of what heuristics are used to select the particular sorting algorithm
are effectively (and thankfully) opaque to the web application developer. The
task of sorting is abstracted to only the task of writing a comparator function
which returns -1 (out of order), 0 (equal order), or 1 (in order).
The example of filtering a list of strings into a list containing only vowel-initial words is just the beginning of the sorts of analysis that can be carried out on structured ling
uistic data.
Morphosyntax
Sociophonetics
Variation
Phonology
This section’s title is a reference to the fact that data which are presented in a layout which implies structural relationships between pieces of information — that is, it implies data structures — may nonetheless fail to encode those data structures explicitly in any persisted format (such as a saved file or a database). To a computer, all data is ultimately just a sequence of characters, and if that sequence is not encoded in such a way that hierarchical relationships can be recovered from it, then those relationships are essentially lost. It is in this sense that one might say that “computers don’t have eyes”: while a human reader may understand data structures that are implicit in visual structure, a computer cannot.
Thus, although it is clear enough that it is possible to conceptualize documentary data as a data structure (as was discussed above for the bilingual clay tablet and Manchu pentaglot dictionary), it is a very different task to implement an actual user interface which can be used to view or modify such data structures in an efficient and intuitive way.
This chapter begins with an introduction to the “Open Web Platform”. Briefly, it is a standard which defines four distinct syntaxes, each of which captures a particular aspect of web applications and data management:
At this point, the syntax of JSON will already be familiar from the introduction in Chapter 3.
This syntax, identifiable by the presence of tags contained within angled brackets, is the most fundamental syntax for the web. It is partially comparable to a normal word processing file, except that it is a markup language rather than a so-called “WYSIWYG” file format. In a word processing file, if a user wants to set a certain stretch of text in a bold typeface (like this), then the user selects the text and presses a button that applies bold formatting. The text then immediately “turns” bold. This is what is meant by the abbreviation “WYSIWYG”: “what you see is what you get.”
In HTML, by contrast, all information related to the structure of the document is itself explicitly encoded into the document as text. The following snippet of HTML also “bolds” a single word:
<p>like <strong>this</strong></p>
.html filename suffix.
The sequence <strong>this</strong> contains both a single tag —
in this case, the tag strong — and some tagged content, in this
simple example, the word this.
In order to “see” the bold text, one must view the file through a program called a web browser. There are many such programs, but the primary browsers in use today on the desktop are Mozilla’s Firefox, Microsoft’s Edge, Google’s Chrome, and Apple’s Safari.
The single line above, then, would be rendered by a browser as follows:
like this
At first blush, this more explicit encoding of document structure may seem to be a step backwards from the WYSIWYG approach, but as we shall see, the opaque way in which document structure is captured by word processing programs is nowhere near as powerful a basis for building interactive user interfaces as HTML and its associated syntaxes.
The HTML standard defines a vocabulary of basic tags for “marking up” many useful sorts of structures within a document: lists, paragraphs, document sections, buttons, etc.
Note that the “bolded” content in the previous example was not tagged
with a tag called “bold,” but rather “strong.” This reflects a key
principle of the Open Web Platform (a principle which itself has
evolved over the course of development of web standards): the separation of content and
presentation. The presentational characteristics of any tag in an
HTML document can be customized through the use of style rules. For
instance, a CSS author might decide for some reason to express the “semantic” idea of
‘strong’ text by overriding the default styling for the <strong> tag to red text
rather than bold text.
A CSS rule to carry this out would look like this:
strong {
font-weight: normal;
color: red;
}
Here, the font-weight property is reset from the default value of bold
to normal, and the color property is set to red (overriding the
default black).
In this section I will explain enough of the workings of CSS for the reader to understand how to lay out basic application interfaces, and to style text according to standard conventions in documentary linguistics (including Leipzig glossing notation).
Another important distinction between the OWP and other data-management applications is that browsers have a complete programming language “baked-in.” This means that the tagged elements in an HTML document may be programmed to interact with user input: clicking, moving the mouse, typing, or some combination of these.
This fact has tremendous consequences for working with data of all sorts in documentary linguistics: it means that it is possible to design custom applications with user interfaces designed specifically to make particular annotative or analytical tasks more efficient. A primary design goal of the DLx codebase is simplicity: the entire library for the primary data structures is currently at less than one thousand lines of code (fewer than ten printed), and while some remain to be elaborated, it is my hope that it will remain within that scale.
The most advanced programming technique introduced in the dissertation
is the the notion of a class. In programming, the term has a
specific meaning: classes a sort of “blueprint” for a particular
object which binds data and behavior (in the form of functions) together.
For each of the basic linguistic data types (Word, Phrase, Sentence, Text,
Corpus, Lexicon), a class will be defined which associates appropriate
methods with the data which constitutes an instance of that class. Thus,
for example, we might define a Phrase as containing at least 1) a string representing
a transcription, 2) a string representing a free translation, and 3) an array of
Word objects, each with their own internal structure.
While this data is the “raw material” of an object which can be stored in JSON,
in order to add “behavior” to a Phrase class, we include functions which can
operate on that data. So a particular phrase (in programming, we refer to an “instance”
of the Phrase class) will not only serve to bind a particular transcription, translation,
and word array together (JSON objects already do this, in essence), it will also have
methods such as .tokenize() or .transliterate() which give that instance of the
class the ability to carry out particular linguistic operations.
Thus, the specific implementation of Digital Linguistics developed in this chapter is
a library of classes which not only encapsulate linguistic data into a useful hierarchy,
it “builds in” familiar conceptual to instances of those classes. To take a simple example,
assuming the class definition for a Phrase object to be developed in the chapter is
already complete, it might be instantiated and used in the following way:
let sampleSentence = new Sentence({
"transcription": "kómo te βa",
"translation": "how’s it going?",
"words": []
}
Notice that our sample sentence was instantiated with an empty words array: that is
to say, this sentence has been neither tokenized nor glossed. Because it is an instance
of a Phrase class, however, the instance has methods:
sampleSentence.tokenize()
Now, if we were to inspect the value of the .words array (by referring to sampleSentence.words
at the Javascript console or in some rendered context), we would see:
[
{ "token": "kómo", "gloss": "" },
{ "token": "te", "gloss": "" },
{ "token": "βa", "gloss": "" }
]
Here we see an array of words with tokens specified, but empty gloss attributes. Assuming again
the existence of a Lexicon instance (let’s call it spanishLexicon) which contains
Spanish words and their glosses, then the .gloss method of the Phrase instance can be
called with said lexicon as a parameter, thusly:
sampleSentence.gloss(spanishLexicon)
Once this method has been executed on this phrase instance, we end up with a data structure like the following:
{
"transcription": "kómo te βa",
"translation": "how’s it going?",
"words": [
{ "token": "kómo", "gloss": "how" },
{ "token": "te", "gloss": "2S.ACC" },
{ "token": "βa", "gloss": "go.3S.PRES" }
]
}
Now we have a reasonably complete representation of this phrase, with sufficient information for a basic interlinear gloss representation of this Spanish sentence. There is much more to be said about the design and especially interactions of these classes and their functionality, but it is hoped that this brief introduction is sufficient to give an idea of the sort of work involved in developing the full library of classes for collecting and manipulating documentary data structures.
Having explained the characteristics and functionality of the classes, I turn to
the topic of how to build user interfaces (in this case, web applications)
which give various interactive forms, or views, to these classes.
Views are responsible for “drawing” or rendering the content of a class instance
to the browser screen in some meaningful way — with the vague word “meaningful”
being used advisedly: one of the most powerful aspects of the open web platform
is the manner in which it enables an almost endless range of presentations.
In general, then, the whole process of designing an application which enables an end-user to view, manipulate, analyze or create documentation is as represented in the following diagram:
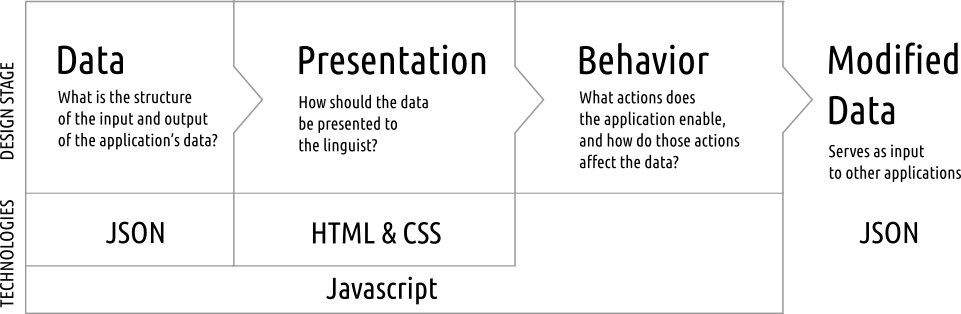
Each of three stages of application design — definition of data, presentation of information in an interface, and the behaviors which make that interface interactive — is in turn associated especially with one or more of the four technologies of JSON, HTML, CSS, and Javascript. While in practice these are all mixed in varying degrees in every stage, this is a useful pedagogical approach.
Note also the key fact that both the beginning and end of this work flows takes the form
of data which is stored in the JSON format. Summarizing and simplifying, one might
think of a DLx application a tool which takes input in the JSON format, and either transforms
it or rearranges it in some useful fashion, and then produces either an unchanged JSON structure
(in the case of applications which do nothing more than format the data in some useful visual
fashion) or a changed JSON structure. For instance, an application whose purpose is to add
part-of-speech tags to a Lexicon instance might take in a Lexicon instance with words
containing only token and gloss values, but output a Lexicon where each word has a wordClass
attribute with particular value.
The actual behavior of such a part-of-speech-tagging application could be defined in many ways, while the input and output JSON might have exactly the same formats in each of those applications’ workflows.
At this point we will have considered the longstanding utility of key data structures in linguistics (Chapter 2), a model of digitized versions of such data structures and how to use them in linguistic analysis (Chapter 3), and an introduction to how to build user interfaces for manipulating such data structures (Chapter 4). In this chapter (almost certainly the longest in the dissertation), I will describe in detail the design and implementation of a minimal but powerful set of basic applications for Digital Linguistics.
There are many ways to present and interact with the most fundamental
unit of language documentation, the Text.
This is the simplest text interface: no word-level morphological analysis is rendered. The sample below is currently in use in a pilot project for the diasporic Mixtec community in California. Note that for the purposes of this project, the community is not interested in morphological analysis. Hence, glosses are not rendered.
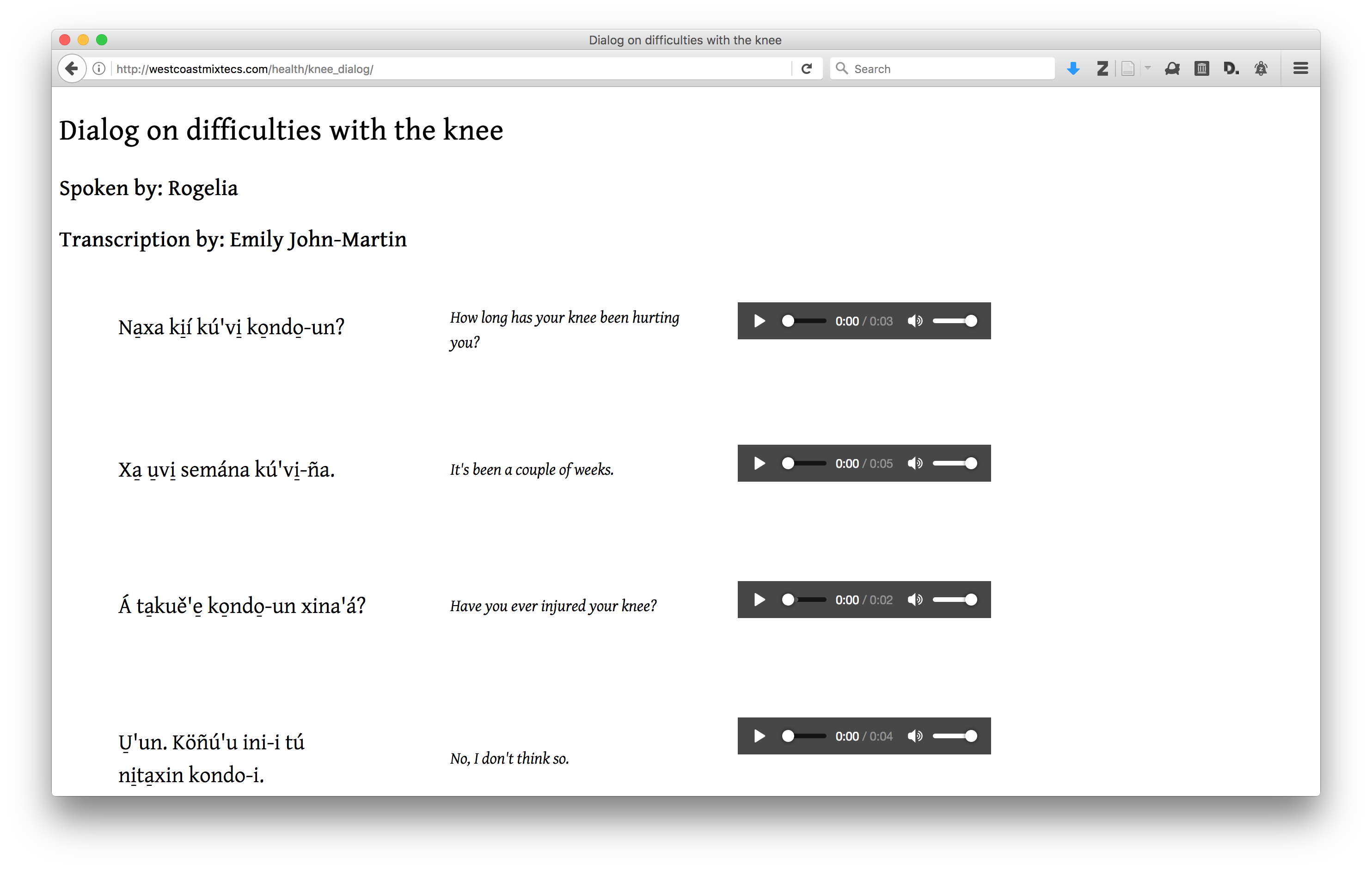
Data Structures: DLx Text
Presentation: Simple parallel text view with basic metadata, a “Play all” button, and a views of each phrase, with transcription, translation, and a phrase-level audio player.
Behavior: User can play any individual line to hear it, or play the whole text.
Example: http://westcoastmixtecs.com/health/knee_pain/
Sample data:
{
"metadata": {
"title": "Dialog on difficulties with the knee",
"source": "MedicalSpanish.com",
"speaker": [
"Rogelia"
]
},
"phrases": [
{
"media": "audio/2016_04_30_Rogelia_knee_pain_01.mp3",
"transcription": "Na̠xa ki̠í kú'vi̠ ko̠ndo̠-un?",
"translation": "How long has your knee been hurting you?"
},
{
"media": "audio/2016_04_30_Rogelia_knee_pain_02.mp3",
"transcription": "Xa̠ u̠vi̠ semána kú'vi̠-ña.",
"translation": "It's been a couple of weeks."
},
{
"media": "audio/2016_04_30_Rogelia_knee_pain_03.mp3",
"transcription": "Á ta̠kuě'e̠ ko̠ndo̠-un xina'á?",
"translation": "Have you ever injured your knee?"
}
]
}
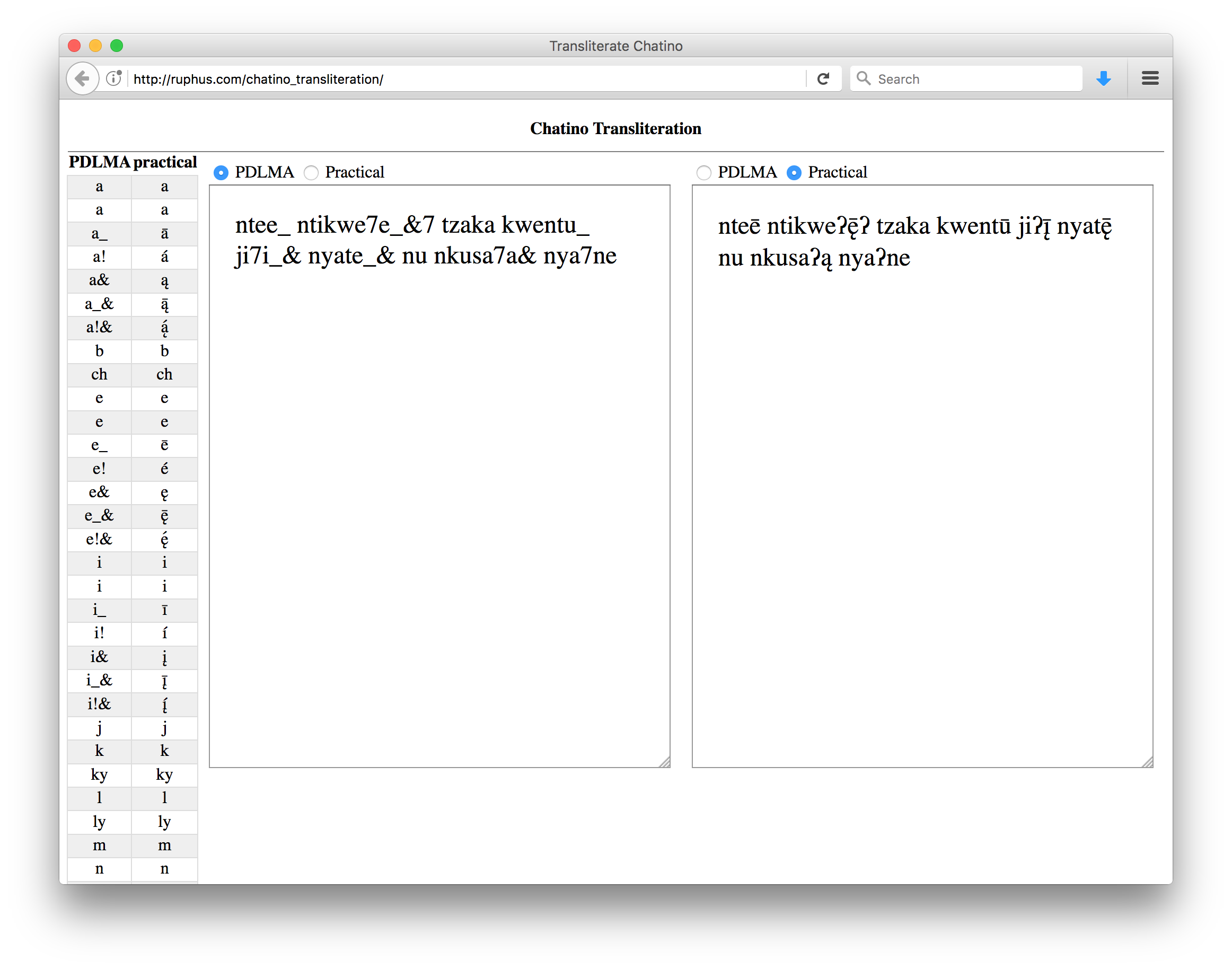
Note that it is equally feasible to render a text which does have morphological glosses, as in this presentation of a text in Ubykh:
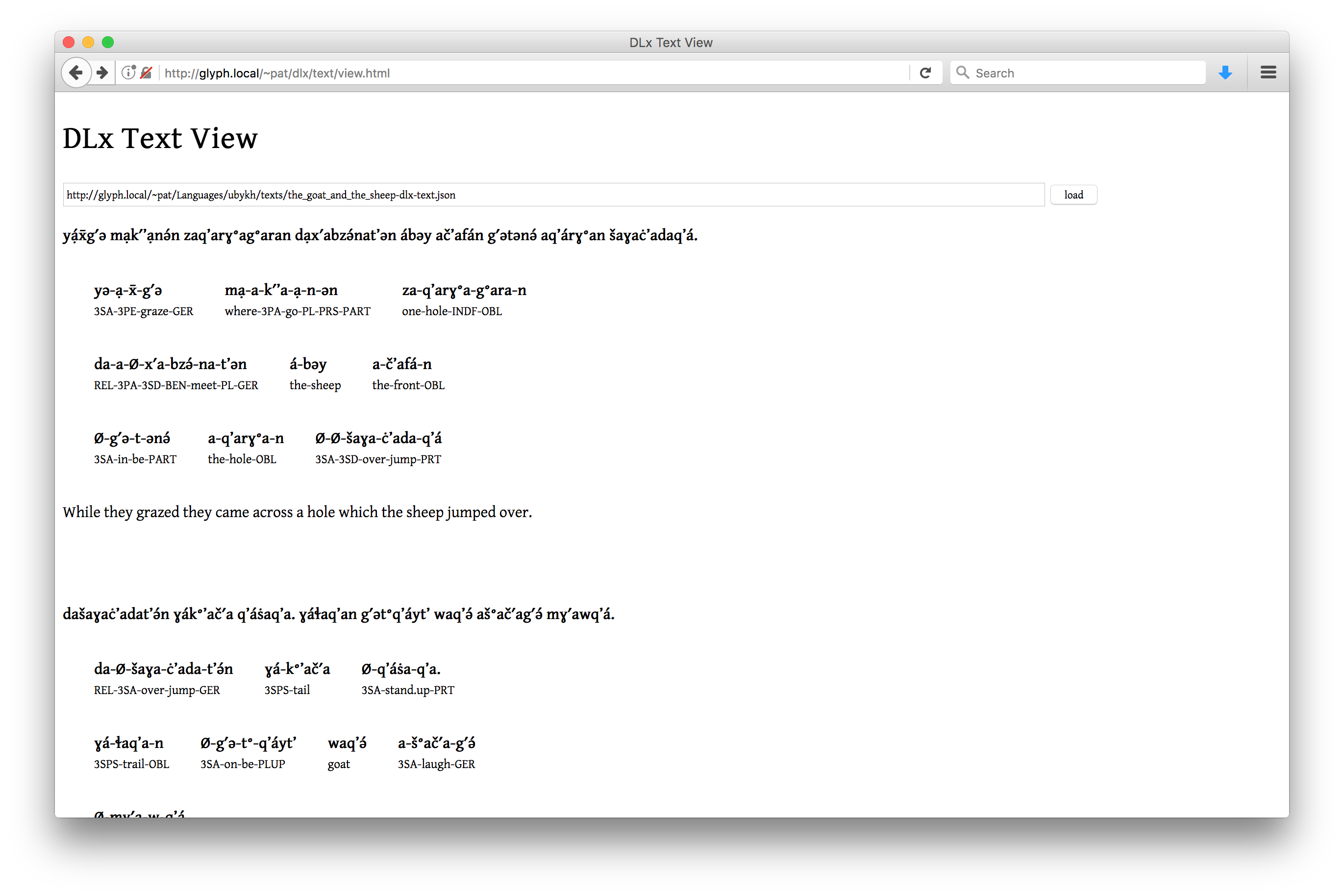
This interface serves to load a JSON file in the DLx Text
format in a readable format.
This interface is designed to be used in a context where fieldwork is already ongoing on a language, and both an orthography and the beginnings of a lexicon have been produced.
Data Structures: DLx Text, DLx Lexicon, DLx Language
Presentation: Standard Interlinear text format with media playback buttons
Behavior: User can play any individual line to hear it, or play the whole text.
Example: http://westcoastmixtecs.com/health/knee_pain/
Sample data:
In this somewhat articial example, a linguist is using standard Spanish orthography to transcribe and morphologically annotate a few sentences in Spanish, presumably in the presence of a speaker. Note that a (small) lexicon is rendered in the left sidebar
Sample Interface
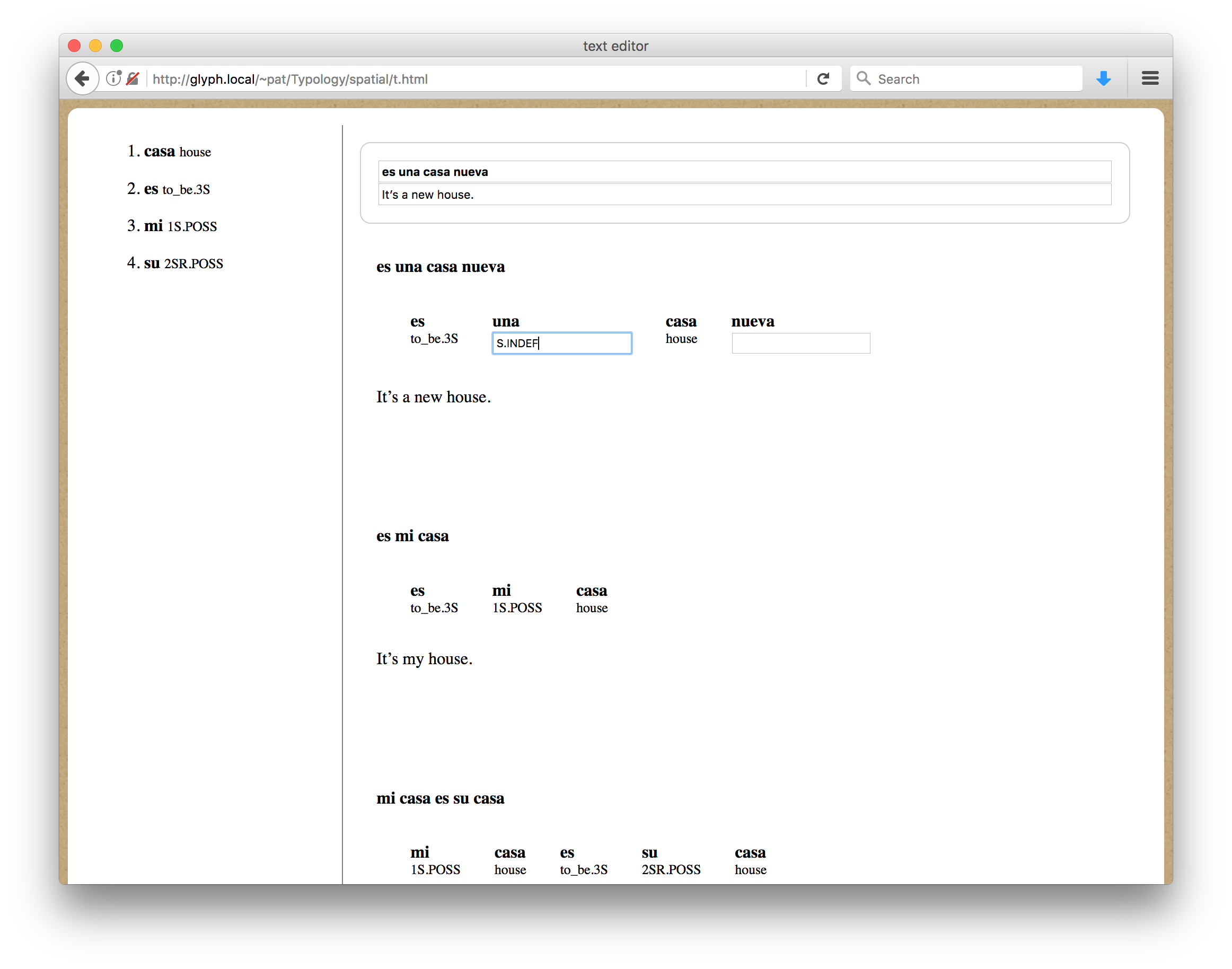
Note that in combination the parallel text interface and the fieldwork editor interface serve to demonstrate that the very same data structure (a DLx text) can be rendered in static or editable forms.
Because the data for DLx applications is contained in distinct JSON data files, the same data may be used for purposes other than traditional linguistic analysis. Many such uses are applicable to the process of language revitalization: the screenshot below displays a set of printable, educational playing cards which were designed for the use of the Mixtec community in Oxnard, California, using data produced by the 2015-2016 field methods class at UCSB. Note that this presentation has exactly the same input as a simple Lexicon viewer — only the rendering code is distinct.

Dealing with large phonological inventories such as that of a language
like Kashaya Pomo can be challenging. An interface I have been working on
makes the enumeration of that phonological system a matter of point-and-click,
and the application edits an instance of the Language data type.
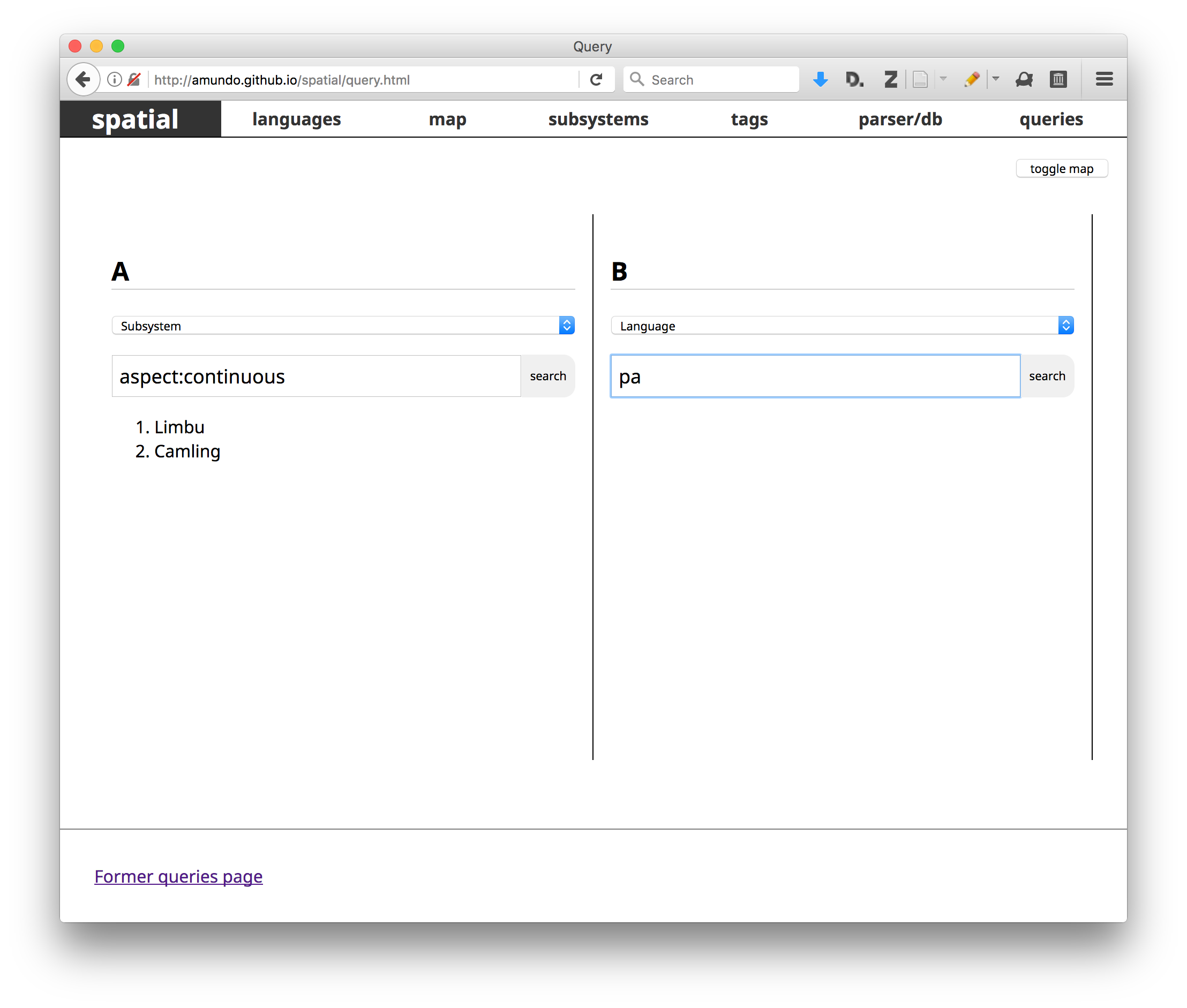
Returning to the notion of the 3-stage workflow in the previous chapter, the
goal of this behavior may be defined as taking as input an array of objects,
each of which corresponds to a “phone” as represented by the IPA, and producing
as an output an array which is a subset of that initial array, containing only
those phones which are known to exist in the language under study.
This in-development application could serve as the basis for an introduction to the utility of the notion of “tagging” across a hierarchical corpus.
The project described by this dissertation is a broad one, with many moving parts. It may help to review what Digital Linguistics is and is not.
…IS a software system with a specific implementation. DLx is an approach to digital language documentation, and it’s an opinionated approach, insofar as it is based on a particular software platform. However, that platform is the platform on which browsers are based, and therefore it is the most reliable, tested, extensible platform in the history of technology.
…IS both technology and pedagogy. Education on the technological underpinnings of DLx is part and parcel of its design: if we are to create a truly sustainable ecosystem for building and using interoperable language documentation, then we must learn together. Participants in DLx must be willing to try to push their own envelopes of technical understanding. DLx is free, but it’s not a freebie. Pedagogy will be provided, but participants must participate.
…Is NOT a single website. DLx is not a .com or a .org or a dot anything. There is a small library of HTML, CSS, and Javascript code which is available as a zipped folder, and which serves as a useful introduction to the principles of DLx. This code is useful without an internet connection — it works offline. We aim to output many formats which are shareable on the internet in a variety of ways, but this does not mean that there will be a single website where you are “expected” to upload anything. Individuals and individual communities must remain in control of where, which, and whether they share any of the work they produce with DLx. Issues of sharing language and “data” are ethical questions, not technological questions, and they cannot be solved by technology.
…IS a set of core applications, but is NOT a single application.
…Is NOT designed to enforce the adoption of some particular theory of language on its users DLx is a system for doing documentation. As such, it encodes the data structures which together comprise the primary sorts of data in language documentation. Arbitrary anntoations can be added to any level of the analytical hierarchy—up to and including parallel structures for more complex systems such as constituency or syntactic analysis—but such additional structures are expansions to the core of DLx.
_…Is NOT a single application. While DLx has as a goal the implementation of basic interfaces for the key documentary tasks of interlinear transcription, morphological analysis, lexicography, and time alignment, it does not follow that there is one “DLx App.” The community will be free to determine how multi-functional a given DLx application is, but DLx will never be equatable with a single application.
…Is NOT the property of anyone. DLx is a software system. It is not an archive. The licensing of documentation which is produced, modified, or analyzed with DLx tools is completely separate from DLx tools themselves. I will strive to include functionality which expedites the proper citation and citability of documentation produced in DLx.
…IS meant to be fun. This document has been written in a rather legalistic, small-print fashion, because these ideas are crucial — indeed, criterial — aspects of DLx. But I hope that bringing DLx to life will be a fun, participatory project which foregrounds the best aspects of documentary linguistics: respect and fascination for the full diversity of human language; satisfaction in collaboration between participants carrying out a variety of roles, and, above all, the valorization of the voices of real people who choose to share their languages with the world.
I think this is doable in one year. I’m thinking of the project, ideally, as a three stage project: chapters 1-3 are the “setup” and hopefully faster part of the process; chapters 4-5 are the real work, and chapter 6 is a hopefully brief wrap-up.